A local TTS production tool with integrated voice quality scoring. Built for consistency, not just generation — because a voice that sounds different every run is useless in production.
The Problem
TTS Is Easy. Consistency Is Hard.
Modern TTS engines can generate impressive speech from text. But ask the same engine to say ten different sentences with the same voice — and you'll get ten slightly different speakers. Pitch shifts, timbre drift, pacing changes. For a single demo, that's fine. For a game with 200+ voice lines that need to sound like the same character, it's a dealbreaker.
AudioGen Studio was built to solve this: generate speech locally, measure consistency scientifically, and only keep what passes quality thresholds.
Core Innovation
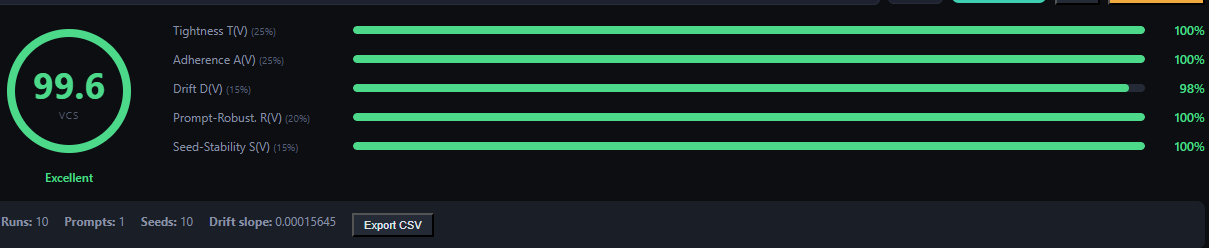
Voice Consistency Score (VCS)
A 5-metric evaluation framework that replaces subjective "does this sound right?" with quantifiable, reproducible measurements. Based on MFCC speaker embeddings (80-dimensional vectors), the VCS answers one question: is this still the same voice?
VCS Dashboard — 99.6% overall score across 10 runs with all 5 sub-metrics visualized.
Metric
Weight
What It Measures
Tightness
25%
How closely clustered are the embeddings? Tight cluster = consistent voice.
Adherence
25%
Does the output match the reference voice? Measures identity preservation.
Drift
15%
Does the voice change over time? Detects gradual quality degradation.
Prompt-Robustness
20%
Does the voice stay consistent across different text inputs?
Seed-Stability
15%
How much does the random seed affect the voice identity?
Capabilities
What It Does
AudioGen Studio is a full production pipeline — from text input to mastered audio output, with quality measurement at every step.
Free Mode
Manual text-to-speech with multi-speaker support, 56 voices (EN/DE/IT), 8 built-in presets, seed locking, and real-time preview.
Game Mode
Load a game JSON, auto-detect format, queue all audio items. Step-through or batch processing with SSE progress streaming.
Voice Designer
Generate custom voices from text descriptions. "A deep, rugged male voice with a slow cowboy drawl" → instant voice, auto-scored via VCS.
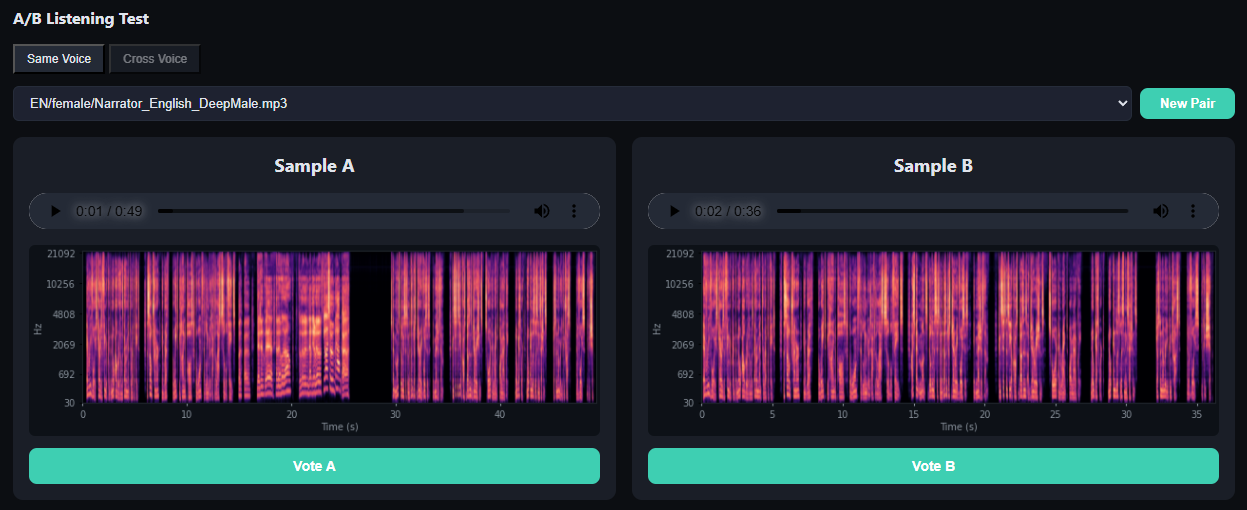
A/B Listening Test
Blind comparison with spectrograms and cosine similarity. Data-driven voice selection instead of subjective guesswork.
Voice Score Mode
Automated N-run evaluation with early abort. Tests a voice across multiple generations and recommends: Production Ready, Acceptable, or Needs Work.
Experiment Tracking
Every generation is recorded: embedding, metadata, audio, prompt. Enables reproducible measurement across runs, sessions, and seeds.
Quality Assurance
Measure, Don't Guess
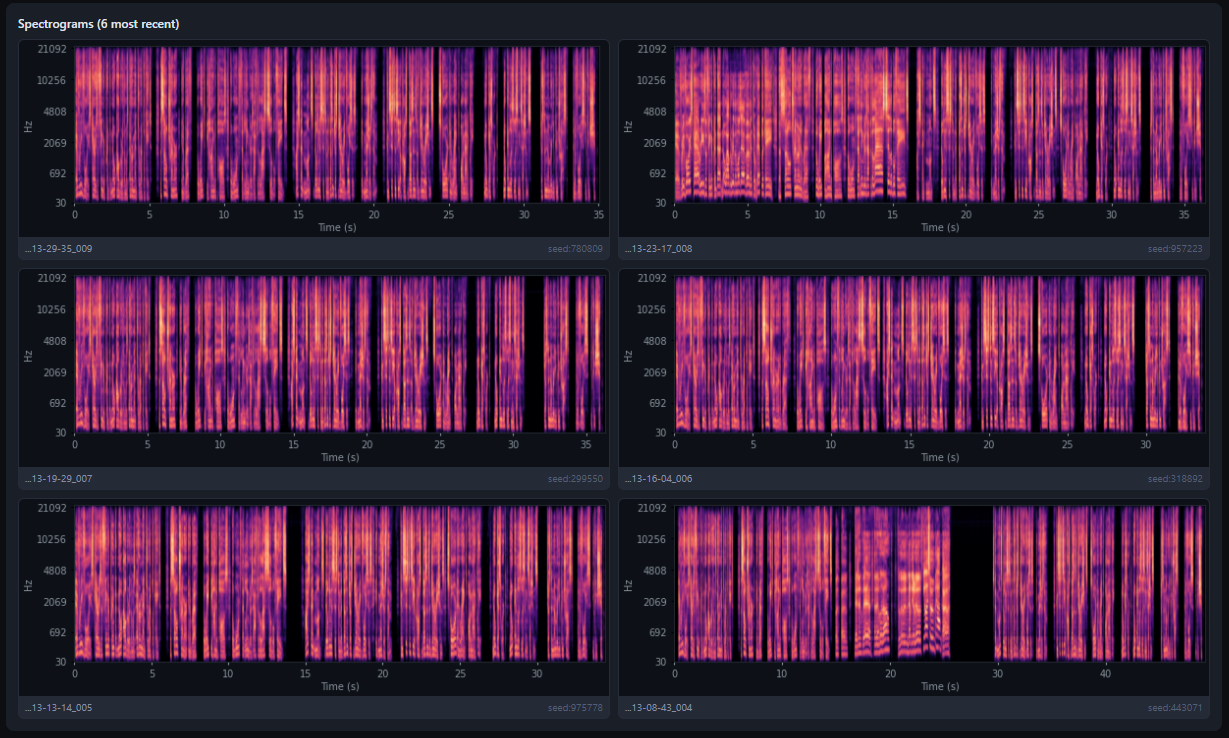
Spectrograms reveal what the ear misses. The A/B test lets you vote blind, then reveals the cosine similarity score — often the numbers disagree with your gut feeling.
A/B Listening Test — blind voting with spectrogram comparison.
Spectrogram grid — 8 runs of the same voice, visually comparing consistency.
Outlier Analysis — 99.8% Trimmed Tightness with 1/10 outlier detected and excluded from scoring.
Audio Pipeline
From Text to Mastered Output
Every generated audio goes through a deterministic post-processing chain. The goal: broadcast-ready output, normalized to -16 LUFS, with no manual editing required.
AudioGen Studio isn't a prototype — it has produced hundreds of voice lines for shipped products, with measurable quality at every step.
56 Voices
39 English, 16 German, 1 Italian — plus unlimited custom voices via Voice Designer.
VCS 99.6%
Peak consistency score achieved across 10 runs. Production-ready threshold is 92%.
200+ Lines per Game
Battle-tested on real game productions with narrator, NPC, and combined dialogue tracks.
What's Next
Enterprise Vision
The VCS framework is designed to become a standalone evaluation tool. The goal: pip install vcs-voice — three lines of code, automated TTS quality evaluation at scale. Replacing manual crowd-worker evaluation with reproducible, quantifiable metrics.